
Antes de llegar a una respuesta a la pregunta planteada me gustaría analizar uno de los ejemplos más resplandecientes del poder del Big Data.
Considerando mi experiencia particular, en los tres últimos eventos a los que he asistido se ha puesto el mismo ejemplo de éxito de Big Data. Me estoy refiriendo a Google Flu Trends (GFT). Si no lo conocéis; cosa que dudo bastante, se trata de un modelo para predecir los brotes de gripe en determinados países, entre los cuales se encuentra España.

Google Flu Trends
Lo cierto es que a primera vista el propósito de este modelo es genial, la única duda es si realmente es el propósito de determinar los brotes de gripe el objetivo principal del modelo. Según mi opinión, Google y todo su poder tecnológico han querido demostrar el poder de la tecnología para resolver problemas muy humanos, pero poniendo la base fundamental en la propia tecnología.
Pero comencemos por el principio. ¿Qué hace que todos los expertos consideren que éste es un ejemplo genial del uso del Big Data?
En este sentido creo que está muy claro, usando Big Data:
- Tiene una forma rápida y barata de capturar información de los usuarios. Olvidándonos de tediosos formularios o encuestas.
- Utiliza un gran volumen de datos y además de fuentes diversas. Son también datos no estructurados. En general se trata de entradas en Blogs y mensajes en las redes sociales.
- Analiza on-line el sentimiento de toda esta información y la convierte en un modelo predictivo de rápida respuesta.
Hasta ahora teníamos al Center for Disease Control (CDC), quien por contra:
- Utiliza una forma lenta de captura de la información. Básicamente formularios de los pacientes en salas de consultas y hospitales.
- La información tiene que ser completamente estructurada y dirigida.
- El análisis requiere de unos plazos determinados.
Para cerrar el círculo el modelo de GFT se construye basándose en una correlación fuerte con los datos históricos del CDC. Así pues, el modelo a extrapolar es como un caramelo en la puerta de un colegio para una empresa:
- Información barata disponible. Nunca antes hemos tenido a nuestra disposición la cantidad de información de la cual disponemos en la actualidad.
- Posibilidad inmediata de predicción y detección de oportunidades de negocio.
- Beneficio asegurado y dirigido a nuestros potenciales clientes.
¿Problemas?
Evidentemente esto suena maravilloso, pero que es lo que se ha detectado en los últimos estudios de este modelo. Parece ser que este modelo no ofrece muy buenas predicciones. En particular tiene un 93% de fallos en la predicción, el modelo equivocó la predicción en 100 de 108 semana. Según los estudios, en algunas ocasiones la predicción fue del doble a la que después se llego a producir. Os dejo aquí un par de enlaces que hablan de estos estudios: (27/03/2014) – Google Flu Trends is no longer good at predicting flu, scientists find. y (22/06/2014) – Usted sabe más que Google.
Con estos datos, este ejemplo para una empresa plantea serias dudas de validez, y es que tal vez las oportunidades de negocio que puedan ser detectadas con un modelo similar, pueden tener también un porcentaje de fallos del 93%. Por lo tanto, por una parte el modelo ya no sería tan atractivo desde el punto de vista del posible beneficio a obtener. Pero por otra parte, todos los expertos indican que el Big Data si que es una verdadera oportunidad de negocio. ¿Qué pasa con GFT?
¿Dónde están los problemas en el GFT?
Según mi opinión los problemas son 4 y voy a tratar de explicarlos lo más sencillamente posible:
- Calidad y validez de los datos.
- Incumplimiento de las condiciones científicas de un experimento.
- Correlación no implica Causalidad.
- La Base fundamental del proyecto es la Tecnología.
Calidad y Validez de los datos
Ésta es una de las 4 dimensiones principales del Big Data y creo firmemente que es la más importante de ellas. Los problemas en la validez de la información viene por dos vías:
- La tendencia de los usuarios a no compartir sus datos sin recibir nada a cambio. Los usuarios limitan lo que comparten y en muchas ocasiones dan respuestas equivocadas conscientemente.
- El propio algoritmo de búsqueda y la característica de Google de «autosuggest» que influye en los resultados.
Google’s own autosuggest feature may have driven more people to make flu-related searches – and misled its Flu Trends forecasting system. Photograph: /Guardian
Esto implica que los datos no son limpios, por lo que en estos proyectos será necesario invertir mucho más en la limpieza de la información antes de iniciar cualquier análisis.
Incumplimiento de las condiciones científicas del experimento
Todo estudio experimental requiere de una condiciones que aseguren en su cumplimiento la certeza de los resultados y de las inferencias que el modelo predice. Es necesario que se cumpla una doble validez tanto interna como externa del estudio o experimento (Cook y Campbell 1974):
- Validez Interna: Existe una relación causal clara. Pueden eliminarse cualquier otra alternativa a los mis hechos probados.
- Validez Externa: La extensión de los resultados pueden generalizarse a otros sujetos o situaciones.
En este punto podríamos llegar a extendernos ampliamente pero analizaremos tan solo algunos de los puntos en los que falla el GFT desde el punto de vista de un experimento científico.
Validez Interna
Historia y efecto de la información
La ocurrencia de acontecimientos externos afecta al comportamiento, un brote de gripe en un determinado lugar puede generar búsquedas relacionadas únicamente con el interés informativo. El saber que existe la herramienta tan promocionada de Google y la curiosidad que esta despierta también verá afectado sus propias predicciones.
Instrumentalización
La forma en como se capturan los datos, el propio Autosuggest que comentábamos anteriormente influyen en el resultado. Hemos de tener también en cuenta la semántica de las búsquedas y el conjunto de búsquedas que se utilizan para el análisis de los resultados.
Mortalidad experimental
Se refiere a la pérdida de sujetos a lo largo de la vida del experimento. Cuando un usuario consulta los síntomas en Internet, la próxima vez que vuelva a tener los mismos síntomas probablemente no vuelva a consultar y estaremos perdiendo un posible dato útil para la predicción.
Selección sesgada de sujetos
La selección de los posibles sujetos de estudio puede parecer en un principio aleatoria pero si analizamos la situación quizás nos demos cuenta que los sujetos son sesgados y no completamente aleatorios. Veremos esto en más detalle en los factores de validez externa.
Validez Externa
Representatividad de los sujetos utilizados.
Los sujetos realmente no son aleatorios y esto no nos permite realizar una extrapolación general con las suficientes garantías. Las razones para afirmar esto son las siguientes:
- Los grupos de riesgo de la gripe
- Uso de Internet por rango de edades en España
Los grupos de Riesgo de la Gripe
Teniendo en cuenta que las personas con buen estado de salud se recuperan de la gripe sin mayores complicaciones, su tendencia a comentar su estado en las redes sociales será menor que la de los posibles grupos de personas con alto riesgo de complicaciones, y los cuales son los siguientes (más detalles):
- Personas de 65 años o mayores
- Niños entre 6 y 23 meses de edad
- Personas con enfermedades crónicas
- Mujeres embarazadas
Uso de Internet por rango de edades en España (Datos del INE)
Simplemente indicar los siguientes datos:
- En España el 71% de la población entre 16 y 74 años a usado internet en los 3 últimos meses
- Solo el 22% de la población entre 65 y 74 años a usado internet en los 3 últimos meses
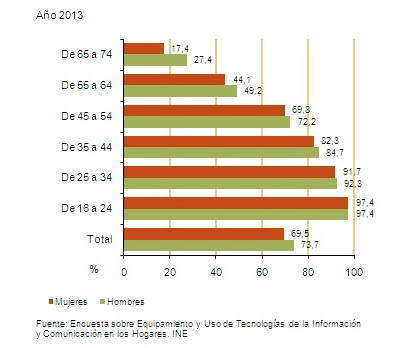
Acceso Internet España 2013 por Edades. Datos del INE
Así pues, considerando que los dos principales grupos de riesgo tienen un acceso bastante limitado a Internet, quizás la muestra de extrapolación puede estar un poco sesgada. ¿No crees?
Posibilidad de repetición de la experimentación en las mismas condiciones
Es claro que con Internet esto no se cumple nunca, el cambio es consustancial a su propia definición. Las condiciones nunca serán las mismas a las iniciales, el contexto cambia constantemente, e incluso el experimentador (el algoritmo predictivo) no es el mismo, se va adaptando y se va modificando constantemente.
En conclusión en mi opinión las condiciones de un estudio o experimento científico no se cumple con GFT, como decía podríamos seguir argumentando muchas más cosas pero es suficiente para un primer análisis.
Correlación NO implica Causalidad
Según el documento «Detecting influenza epidemics using search engine query data (Google GFT)» , en el que podemos leer en su primera página:
«… Because the relative frequency of certain queries is highly correlated with the percentage of physician visits in which a patients presents with influenza like symptoms,…»
Esto quiere decir, que el modelo está basado en una correlación que podría ser o no ser cierta. Además, ya sabíamos que el modelo esta construido en base a una correlación con los datos reportados por la CDC. Y todo el mundo tendría que saber que si dos hechos se producen al mismo tiempo o parecen estar relacionados entre sí, ello no significa necesariamente que uno de los hechos sea causa del otro.
Existe una página muy curiosa Spurious Correlations en la que podremos encontrar correlaciones prácticamente perfectas de variables que evidentemente no tienen ninguna relación. En cualquier caso, como decía «Correlación no implica causalidad, hay que decirlo más para que quede claro»

Para dejarlo más claro podemos ilustrarlo con un ejemplo típico:
» Se ha observado que el consumo de helado, produce mayor número de ahogamientos»
Pues bien, estas dos variables correlacionan perfectamente, ahora bien todo el mundo es consciente que no tienen una relación directa. En este caso existe otro factor que anula la validez interna de la afirmación ya que el aumento de calor es lo que produce tanto el mayor consumo de helado, como la mayor cantidad de baños y por consiguiente de ahogamientos.
El problema principal, la base del proyecto
Creo que el problema principal es que se trata de un proyecto de Big Data que parte de la Tecnología en primer lugar, por contra todo proyecto de Big data tiene que partir de saber que es lo que queremos hacer y enfocarnos al problema específico en primer lugar.
Estoy convencido de que el objetivo real y principal de Google es demostrar el poder el Big Data y como aplicación particular detectar los brotes de gripe. La cuestión es que el modelo se tendría que haber pensado en sentido inverso. Evidentemente esto es una opinión particular totalmente discutible.
¿Y ahora qué?
Llegados a este punto todo parece indicar que estos modelos no serían muy fiables para predecir oportunidades de negocio, pero realmente creo que es todo lo contrario.
Creo firmemente que el poder del Big Data está en construir proyectos en los cuales como decía antes la tecnología no se encuentre en primer lugar. Lo principal es saber por qué hacemos el proyecto y estar enfocados al problema especifico que queremos resolver. Después tendremos que considerar las 4 dimensiones del Big Data que son Volumen, Variedad, Velocidad y Veracidad de los datos, teniendo una especial consideración con esta última. La veracidad y validez de la información son fundamentales y será necesario implementar procedimientos de limpieza y depuración de la información.
Una Gran Oportunidad
En conclusión, considero que Big Data es una gran oportunidad para las empresas, tan solo tienen que construir sus proyectos con una buena base.
Unas citas finales de expertos del Big Data:
«Un proyecto de Big Data no va a producir ningún beneficio a menos que esté enfocado a un problema específico»
Es decir, una buena base.
«Los datos nunca han sido tan baratos como hoy. Solo pueden volverse más costosos»
Usemos los datos pero analicemos su validez e invirtamos en su limpieza y veracidad.
¿Qué opinas al respecto? …
